
The original code was quite a mess, though all things considered, it didn't turn out too bad.
For this version, I had the following goals in mind:
a) Have a unified shader architecture.
b) Work within the limitations of DX9.
c) Add mimaps and anti-aliasing.
a) Unified shader architecture
What I meant by a unified shader architecture is this: Certain effects, such as fog, were originally uniforms, and optional during rendering.
I wanted to move as much of the variable state to compile-time shader permutations that could be combined and runtime, and through a hashing of bit flags that indicate render state, select the appropriate shader for the entire pipeline.
This meant writing a sort of shader compiler that would, in a pre-process step, go through each shader permuation and generate appropriate defines to turn parts of the shader on or off depending on which primary shader was used, and which permutation bits were set.
In total, there were 12 main states, which I will include as code since it's already commented:
enum main_shader_type { // Generic world geometry SHADER_WORLD, // Generic world geometry that uses fullbright textures SHADER_WORLD_FULLBRIGHT, // Alphatest textures SHADER_ALPHATEST, // Quake 1 sky SHADER_SKYSCROLL, // Cubemap skybox SHADER_SKYBOX, // Water, lava, slime, etc... SHADER_TURB, // Like above, but with a wateralpha uniform SHADER_TURB_WATERALPHA, // Solid materials requiring transparency SHADER_TRANSPARENT, // Liquid materials requiring transparency SHADER_TURB_TRANSPARENT, // Material that replaces texture and lightmap with a solid color SHADER_ENV_COLOR, // Blit from one render target to another SHADER_BLIT, // Unused for now? SHADER_FONT, };
and 7 sub states - each main state could effectively have a variant of one of the following:
#define BIT(n) (1 << (n)) #define PERM_GENERIC BIT(1) #define PERM_FOG BIT(2) #define PERM_LIGHTMAP BIT(3) #define PERM_FULLBRIGHT BIT(4) #define PERM_DEBUG_DIFFUSE_COORDS BIT(5) #define PERM_DEBUG_LIGHTMAP_COORDS BIT(6) #define PERM_EARLY_Z BIT(7)
- Generic - No special effects
- Fog - EXP2 fog
- Lightmap - Lightmap only rendering.
- Fullbright - No lightmap contribution.
- Debug diffuse - Render the diffuse texture coordinates.
- Debug lightmap - Render the lightmap texture coordinates.
- Early Z - Z prepass (not used as far I remember).
SHADER_WORLD with PERM_GENERIC and,
SHADER_WORLD with PERM_FOG.
At runtime, if fog was enabled, the second permutation would be used for every frame until the fog was turned off.
The only runtime cost is that hash table lookup to get the correct shader object. The shader itself will have been compiled to exactly what was needed.
A result of this fine-grain control is that the longest pixel shader is only 20 instructions in ps_2_0 assembly, because all flow control had effectively been decided at compile time.
The first time I heard about such a workflow was after reading Valve's presentation on their Half-Life 2 shader generation, named Half-Life 2 / Valve Source Shading, in which they had compile time constants dictate how a shader would perform. According to their presentation, they had 1920 pixel shaders generated via this processes. The presentation can be found here.
My approach only yielded 62 pixel shaders, and many of those were actually duplicates at the assembly level. At shader load time, I would hash each shader and see if an existing version could be reused. After hashing and de-duplicating, I had 36 unique pixel shaders.
This may seems like a lot of shaders, but in reality, only about 4 of these are ever used in a single frame at any given time, so the penalty of shader switching is quite minimal.
To conclude this section, I will include the vertex layout used in the engine for those curious:
// C++ representation // 32 bytes per vertex struct m_vertex { float3 Pos; s16 MaterialID[2]; // Texture coordinates use 16-bit floats to save space. half2 TexcoordDiffuse; half2 TexcoordLightmap; float DiffuseAndLightmapID[2]; }; // HLSL struct vs_in { float3 pos : POSITION; float2 texcoord_diffuse : TEXCOORD1; float2 texcoord_lightmap: TEXCOORD2; float2 texture_id: TEXCOORD3; int2 material_id : TEXCOORD4; }; struct vs_out { float4 pos : POSITION0; float3 color : TEXCOORD0; float2 texcoord_diffuse : TEXCOORD1; float2 texcoord_lightmap : TEXCOORD2; float2 texture_id : TEXCOORD3; #if INCLUDE_INTERP_MATERIAL float4 material : TEXCOORD4; #endif #if INCLUDE_INTERP_FOG float fog_factor : TEXCOORD6; #endif };
b) Work within the limitations of DX9.
I had the idea of writing an OpenGL wrapper for DX9, and translating the shaders with mojoshader, but I've since abandoned that idea and stuck to just DX. I may revisit it in the future.
I faced a number of challenges working within the limitations of DX9. The first was the lack of real integer types. Even though the hardware has long had support for integers, at the API level, this simply does not exist in DX9.
I needed to create an RGBA32F texture to serve as a lookup table for the lightmaps, and was having all sorts of issues sampling from it.
Turns out there are miniscule precision errors during interpolation, even if all values of a vertex for that interpolator are the same.
This resulted in an integer conversion being off by 1 on occasion, and it was driving me crazy.
To fix this, I needed to do the following:
float lookup_id = floor(texture_id + 0.1);
Where lookup_id can now be converted to a 2D texture coordinate that can be used to sample a lookup texture.
After this change, I was able to use this value to sample lightmap coordinates for each face.
Another issue, somewhat related to this was the precision loss when converting from an arbitrary floating point whole value to a fraction for UV sampling.
Suppose we have a 1000x20 lookup texture, where lookup_id is a 1D index.
float2 uv; uv.x = lookup_id / 1000; uv.y = (lookup_id / 1000) / 20; float4 value = tex2D(tex, uv);
That's all well and good, but I found that having the texture dimensions be non-powers of two was causing very strange precision loss.
To work around this, I explicitly hardcoded the texture width to be 1024, and the texture height was padded to the larget power of 2 that accomodates the number of elements in the table.
Our new texture dimensions are now 1024x32, and magically, the precison issues are solved.
c) Add mimaps and anti-aliasing
Originally, I had the idea of packing the diffuse texture into a megatexture and indexing into that using a lookup table. This is exactly what I did in my first version. Problem: It becomes almost impossible to implement accurate mimaps, and take advantage of hardware anti-aliasing features.
I'm sure that using OpenGL's bindless texture extension or using Vulkan would alleviate many of the troubles earlier APIs caused in regards to texture binding.
Alas, as I was still using DX9, I had to give up my nice branchless plan and fall back to one of the original strategies that Quake used to render its world: Texture Chains
The idea is that you would group the world geometry by the texture that it used, render all geometry with that texture, and repeat until all texture groups have been rendered. In psuedocode, it would look something like this:
// Preprocess step for poly in model { polys[poly.texture_id] += poly } // Rendering step. Step through each chain. MAX_TEXTURES_PER_LEVEL is 512 here for texture_id in 0 to MAX_TEXTURES_PER_LEVEL { if(!polys[texture_id].empty()) { bind(texture_id) render(polys[texture_id]) } }
The real code is more involved of course, but that's the basic idea.
Splitting up the world like this allowed me to accurately generate mipmaps for each texture, as well as use MSAA without weird artifacts.
Even with all of these texture binds (a typical level may have about 100 to 200 textures), the performance is still in the thousands of frames per second
on the original id levels using a GTX 670, so it's really not as bad as I had feared. This is also partly due to the very small shader instruction count.
d)Further optimizations
Texture packing
Memory allocator
Like a lot of developers, I ended up writing my own allocator for the runtime of this engine.
It makes a lot more sense, and is far easier to sub-allocate out of a shared memory pool than to keep track of potentially thousands of
std::vectors and on top of that, have to deal with whether it's passed by reference, or pointer, or by value, and whether it will create a copy of itself for any reason.
I had written memory allocators before, but never a general purpose allocator that was actually used in anything but the most trivial code.
As a starting point, I referred to K & R and implemented their memory allocator as a starting point. It can be found in Chapter 8, Section 8.7.
After making my dynamic array class use this new allocator, I found it to be much, much slower than the current CRT version of malloc(). But hey, it did work, and I was not leaking memory anymore.
However, something had to be done about the performance.
After a few days of thinking, I wrote something that I called a slab allocator. I am not sure what the proper name actually is.
Essentially, it's a collection of linked lists. Each linked list in the collection represents an array of equally sized memory slices, which are fixed to a power-of-2.
Refer to the following diagram for the memory layout.
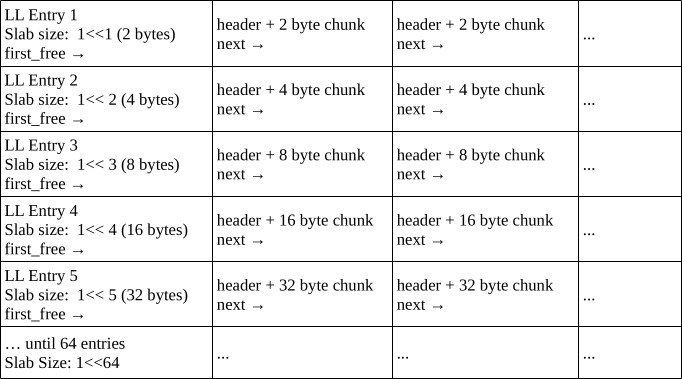
struct slab_header_t { union { struct { // Next free node slab_header_t *next; u64 size; u32 flags; u32 magic; }; u8 pad[32]; }; }; struct slab_table_t { u64 size = 0; slab_header_t *first_free = 0; };
The interface to the allocator is surprisingly simple.
struct slab_allocator { slab_table_t entries[64] = {}; int get_index(u64 size) { // Make sure the size is a power of 2 // Any other size indicates an error in the logic, no slab should have a non-pow2 size. Assert(popcount64(size) == 1); int index = msb64(size); Assert(index >= 0 && index < 64); return index; } bool32 exists(u64 size) { int index = get_index(size); return entries[index].size != 0; } void insert(u64 size) { slab_table_t entry = {}; int index = get_index(size); entry.size = size; entries[index] = entry; } slab_table_t *get(u64 size) { int index = get_index(size); return &entries[index]; } void reset() { memset(entries, 0, sizeof(entries)); } };
When memory is allocated, the size gets promoted to the next highest power of 2 (unless it already is a power of 2).
A neat property of this approach is that looking up the correct linked list of slabs is potentially a constant time operation. msb64() is actually implemented
using the bsr instruction (_BitScanReverse64() when using Microsoft's headers).
Using msb64(), we get the index of the array element, and insert a new entry into the linked list.
The linked list works in LIFO order. That is, the most recently freed item is always at the head of the list, ready to be allocated again.
Refer to the (greatly simplified) psuedocode below
void *malloc(size_t size) { size = next_power_of_two(size); if(!entries.exists(size)) { entries.insert(size); } slab_table_t *entry = entries.get(size); slab_header_t *result = 0; if(!entry->first_free) { result = alloc_header(size); } else { result = entry->first_free; entry->first_free = entry->first_free->next; } // Return the memory after the header return result + 1; }
Freeing is even simpler.
void free(slab_table_t *entry, slab_header_t *header) { Assert(header_is_valid(header)); header->next = entry->first_free; entry->first_free = header; }
After implementing this allocator, the performance was on-par, or perhaps even exceeded the CRT malloc(), and I could stop worrying about memory allocations for the most part.
DXT conversion
Games from the 2000s often used texture compression to save both on-disk memory and runtime memory.
As Quake was written before the advent of mass hardware accelerated texture decompression, it used raw RGB data in its OpenGL version.
I wanted to see what memory savings / performance I could get from compressing the textures.
As the assets are stored in a paletted format, I first converted the data to RGBA. The data stayed this way in the engine for some time, until I decided to give texture compression a go.
The most popular form of texture compression for plain, non-alpha textures, from what I could gather, was DXT1.
To qualify for texture compression, a level texture could not be used for:
- Transparency
- Alphatest
- Sky
- Animation
The following line in the source code checks this with bit flags:
u32 NoDXTMask = TF_TRANSPARENT | TF_ALPHATEST | TF_SKIP | TF_SKY | TF_ANIM;
So, in other words, it had to be a plain ol' texture with nothing fancy going on.
At first, I used the D3DX function D3DXLoadSurfaceFromMemory() as a proof of concept. This worked well, but on levels with a large amount of textures, it was eating into the loading time. I tried multi-threading the code, but the D3DX functions are seemingly not thread-safe by default, so I had to find another way.
Thankfully, there is a very nice library that did exactly what I needed: stb_dxt.h.
Because the memory allocator I wrote was not inherently thread safe, all texture memory had to be pre-allocated in the main thread before being sent off to be compressed. The worker thread generated a complete mip chain, and DXT compressed each mip level if required. This resulted in much faster loading times, both because the compression itself was faster, and because I was taking advantage of multiple threads.
From testing several maps, this resulted in a 30-45% decrease in overall texture memory usage per level.
I did not see any significant performance improvements from regular timing benchmarks, but maybe something would show up in a GPU profiler.
All in all, this was about two months of work on and off.